rga
Line-oriented search tool that extends ripgrep to search inside PDFs, archives, documents, and multimedia files
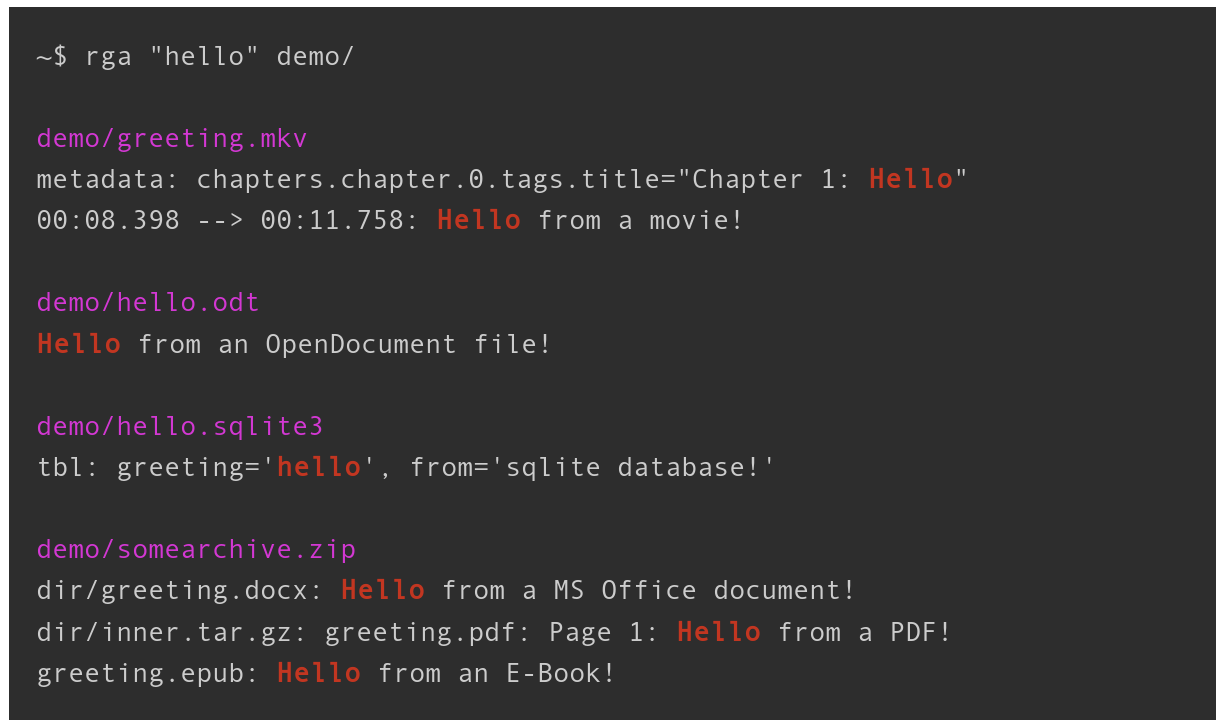
rga (ripgrep-all) is a line-oriented search tool that wraps ripgrep to enable regex searches across a wide range of file formats. While ripgrep excels at searching plain text files, rga extends this capability to PDFs, Office documents (docx, odt), e-books (epub), archives (zip, tar.gz), databases (sqlite), and multimedia files with embedded text like subtitles.
The tool uses specialized adapters to extract searchable text from different file formats. It includes adapters for pandoc (Office documents, HTML, epub), poppler (PDF text extraction), ffmpeg (video metadata and subtitles), and various archive formats. rga recursively descends into nested archives and applies the appropriate adapter based on file extensions or MIME types when using the --rga-accurate flag.
rga implements caching to store extracted text in a local database, significantly speeding up repeated searches on the same files. The cache uses ZSTD compression and can be configured or disabled entirely. The tool integrates with fzf for interactive file searching and supports all of ripgrep's standard options and patterns. It's particularly useful for developers, researchers, and system administrators who need to search across heterogeneous file collections including documentation, archives, and multimedia content.
Installation
# via Homebrew
brew install rga
# via Arch Linux
pacman -S ripgrep-all
# via Chocolatey
choco install ripgrep-all
# via Cargo
cargo install --locked ripgrep_all